文章摘要:随着大数据技术与统计建模方法的不断发展,足球赛前预测正逐步从经验判断迈向数据驱动与模型决策的新阶段。基于多维统计模型的足球赛前数据筛选与精准预测策略研究,旨在通过系统整合球队历史表现、球员个体状态、战术风格、赛程环境及外部变量等多源数据,构建科学、稳定且可解释的预测体系。本文围绕多维统计模型在足球赛前分析中的应用逻辑与实践路径,重点探讨数据筛选机制、模型构建思路、预测策略优化以及结果评估与动态修正等核心问题。通过理论分析与方法论梳理,揭示多维数据融合对于提升预测准确率与稳定性的关键价值,为足球赛事分析、竞技决策支持以及相关研究提供系统化的研究框架与实践参考。
一、多维数据体系构建
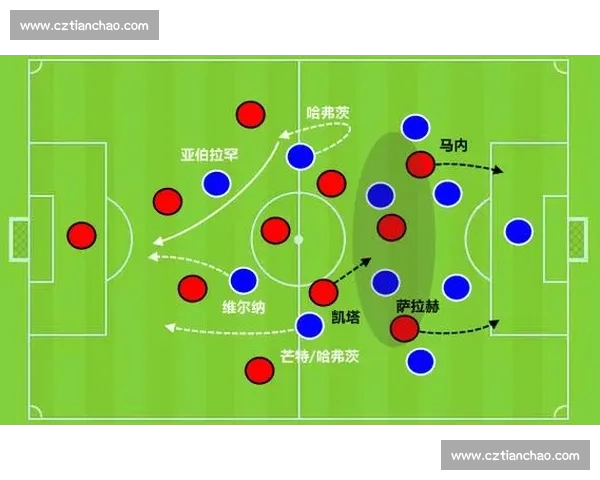
在足球赛前预测中,多维数据体系的构建是整个研究方法的基础环节。传统预测往往依赖单一维度数据,如胜负记录或进球数,这种方式难以全面反映比赛的复杂性。多维统计模型强调从时间、空间、行为和环境等多个角度采集数据,以形成对比赛更立体的认知。
具体而言,数据维度通常包括球队层面与球员层面两大类别。球队层面涵盖整体攻防效率、控球率、阵型稳定性以及主客场差异等指标;球员层面则关注核心球员出勤率、伤停情况、个人技术统计及心理状态。这些数据相互关联,共同影响比赛结果。
此外,外部环境数据也是多维体系中不可忽视的组成部分,如天气条件、比赛场地、赛程密集度以及裁判因素等。这些变量虽不直接体现球队实力,却常常对比赛节奏和结果产生显著影响,合理纳入模型有助于提高预测的现实贴合度。
二、赛前数据筛选方法
在海量数据背景下,如何有效筛选高价值信息是多维统计模型应用的关键问题之一。并非所有数据都对预测结果具有同等贡献,若不加区分地纳入模型,反而可能引入噪声,降低模型稳定性。因此,赛前数据筛选需要遵循科学原则。
常见的数据筛选方法包括相关性分析、方差分析以及特征重要性评估等。通过统计检验手段,可以识别与比赛结果高度相关的变量,从而在建模阶段优先保留这些关键特征,减少冗余数据对模型的干扰。
同时,动态筛选机制也是赛前数据处理的重要方向。不同联赛、不同阶段的比赛,其影响因素权重并不完全一致。通过引入时间窗口与情境变量,模型能够根据最新数据特征自动调整筛选标准,使预测更具时效性和针对性。
三、统计模型与预测策略
在完成数据筛选后,统计模型的选择与构建直接决定预测策略的有效性。多维统计模型通常以回归分析、概率模型或机器学习算法为核心,通过对历史数据的学习,建立输入变量与比赛结果之间的映射关系。
多模型融合策略在实践中具有显著优势。单一模型往往受限于假设条件或算法偏好,而通过组合多种模型的预测结果,可以在一定程度上平衡偏差与方差,提高整体预测的稳健性。这种集成思路已成为现代足球预测研究的重要趋势。
在预测策略层面,还需注重结果表达方式的多样化。除胜负判断外,模型可输出概率分布、置信区间或风险等级,为决策者提供更丰富的信息支持。这种从“单点预测”向“区间预测”的转变,有助于提升预测结果的实际应用价值。
 雷火电竞网页,雷火电竞网页,雷火电竞网页,雷火电竞官网在线,雷火电竞官网在线
雷火电竞网页,雷火电竞网页,雷火电竞网页,雷火电竞官网在线,雷火电竞官网在线四、结果评估与动态修正
预测结果的评估是检验多维统计模型有效性的必要环节。通过回溯分析,将预测结果与实际比赛结果进行对比,可以量化模型的准确率、稳定性及长期表现,为后续优化提供依据。
评估过程中应采用多指标体系,而非单一命中率标准。例如,引入对数损失、Brier评分等概率评估指标,可以更全面地反映模型在不同预测情境下的表现,避免因样本结构变化导致评价失真。
在此基础上,动态修正机制能够使模型不断自我优化。随着新比赛数据的不断积累,模型参数与特征权重可通过在线学习或周期性重训练方式进行更新,从而保持预测体系对现实变化的敏感度与适应性。
总结:
综上所述,基于多维统计模型的足球赛前数据筛选与精准预测策略,是一项融合数据科学、统计方法与足球专业知识的系统性研究工作。通过构建多维数据体系、实施科学筛选方法、优化模型结构并持续评估修正,可以显著提升赛前预测的准确性与可靠性。
未来,随着数据获取渠道的进一步丰富与计算能力的持续提升,多维统计模型在足球预测领域的应用空间将不断拓展。通过不断完善研究方法与实践路径,该策略有望为足球赛事分析、竞技决策支持以及相关产业发展提供更加坚实的理论基础与技术支撑。